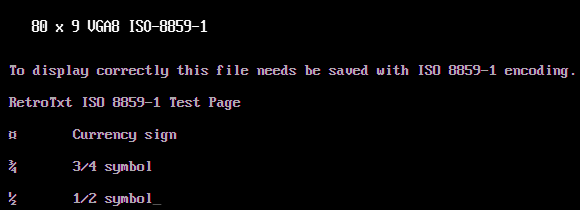
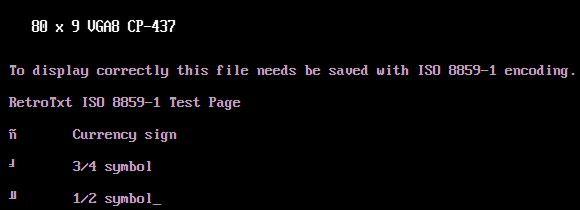
Garbled or illegible text?
There could be many causes for garbled text, but it is generally related to the web server or browser choosing the incorrect character encoding for the text file.
Modern web browsers and documents use the Unicode Transformation Format (UTF), while legacy text files rely on 8-bit codepages that use at most 256 unique text characters or glyphs. UTF decoding is not 100% backward with most legacy text encodings, but unfortunately, most browsers do not have an ideal way to fix this.
RetroTxt can attempt to resolve this by swapping out different characters based on mocking the more common historic character encodings. On a RetroTxt rendered tab, there is a clickable item titled encoding in the tab's information header; clicking this multiple times will cycle through the mock encodings.